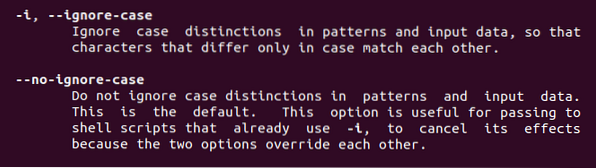
З цієї команди ми знайдемо дві функції, описані вище. -Я маю на увазі ігнорувати регістр, де б не було використано це ключове слово, прихильність до регістру буде видалено.
Обов’язкова умова
Для реалізації функціональних можливостей цієї функції в операційній системі Linux нам потрібно встановити ОС Linux. Після налаштування ви надасте необхідну інформацію про користувача, за допомогою якої користувач буде ввійшов в систему. Крім того, після введення імені користувача та пароля користувач зможе отримати доступ до всіх вбудованих функцій операційної системи. Нарешті, після доступу до робочого столу, вам потрібно отримати доступ до терміналу, оскільки на ньому потрібно запускати команди.
Приклад 1:
У цьому прикладі ми побачимо, як grep допомагає уникнути чутливості до регістру. Розглянемо файл з іменем files11.txt. Файл містить у собі такі дані; як ви можете бачити, слово манго пишеться по-різному, деякі слова містяться з великої літери, а деякі - з малої. За допомогою команди cat ми відобразимо дані файлу.
$ cat файли11.txt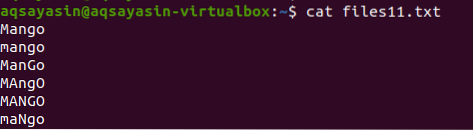
Після того, як команда використовується для відображення даних, можна помітити, що відображається єдине слово, яке відповідає регістру букви, присутньої в команді. Усі літери малими літерами.
Файли манго $ grep11.txt
Тепер, щоб зрозуміти концепцію нечутливості до регістру, ми використаємо “-I” в команді для обробки чутливості до регістру, надаючи всі дані, що є у файлі, і збіги з рядком, що знаходиться всередині команди.
$ grep -Я манго-файли11.txt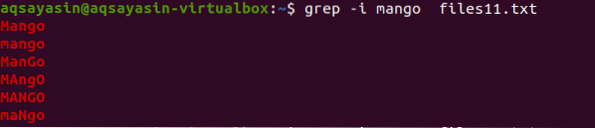
З результату ви дізнаєтесь, що всі дані, що відповідають слову «манго», відображаються або з деякими словами, написаними з великої літери, а деякі - з малої.
Приклад 2
Цей приклад нагадує перший, різниця полягає в тому, що виходить лише одне слово. Ця команда допомагає отримати цілий рядок, зіставляючи його зі словом, вказаним у команді. Давайте мати файл filea.txt. як приклад, ми хочемо отримати запис відповідно до заданого збігу.
$ cat filea.txt
Тепер застосуйте ту саму команду, щоб ігнорувати регістр та зобразити результати. Технічне слово відображається, виключаючи регістр, щоб зробити його чутливим до регістру.

Приклад 3
Інший метод використання grep для ігнорування регістру - це спочатку ввести ім’я файлу, а пізніше застосувати команду -I з grep, слідуючи “|” оператора. Кішка використовується разом з "|". Давайте матимемо файл з іменем file24.txt. як приклад.
$ Cat файл24.txt | grep -Я “Акса”Ця команда отримає слово "Aqsa" як у верхньому, так і в нижньому регістрі.

Приклад 4
Перехід до іншого прикладу. Тут ми відобразимо дані файлу, що містить слово «мій». Тут пошук здійснюється шляхом введення каталогу, таким чином команда сортує слово у всіх файлах із розширенням .txt в системі.
$ grep -Я мій / home / aqsayasin / *.txt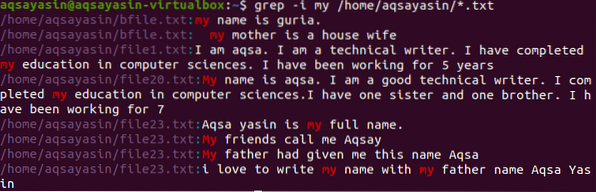
Наведене зображення показує результати, отримані від команди. “Моє” слово виділено, тобто в обох випадках. Деякі файли містять його малими літерами, а інші - великими. Також відображається адреса файлів та імена файлів.
Приклад 5
Цей приклад можна застосувати до каталогу, що містить усі файли. Обмеження застосовуватимуться для відображення конкретного результату, який відповідає слову, яке ми визначили в команді. Слово “is” використовується для пошуку у всіх файлах, присутніх у системі.
$ grep -Я є / home / aqsayasin / file *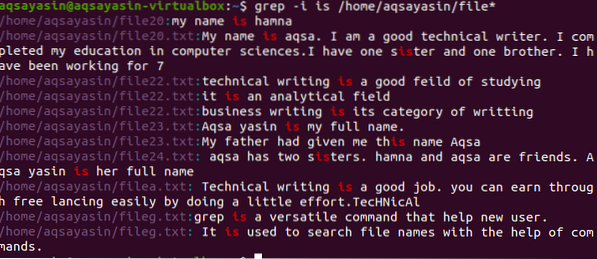
Вихідні дані показують цілі рядки, що містять відповідне слово. Як "є" пишеться окремо або поєднується в іншому слові i.e. сестра.
Приклад 6
Наступна команда показує, як -iw працює разом у команді. Крім цього, пошук здійснюється за двома словами в одному файлі. Зворотна коса риска та "|" використовуються для опису двох слів у файлі, тоді як -w використовується для точної відповідності відповідного слова у файлі.
$ grep -iw 'hamna \ | house' файл21.txtФайл $ grep 'hamn \ | house' 21.txt

-Я проігнорую чутливість до регістру. У наведеному вище прикладі ми бачимо, що наявність -w з -I, дозволяє будинок у першій команді не розглядатись, оскільки -w дозволяє точно збігатися. У другій команді ми видалили обидва -iw, отже обидва слова відображаються після збігу в рядку.
Приклад 7
Пошук кількох слів здійснюється за допомогою іншого методу. Обидва слова шукаються з одного файлу, ці слова - «робота» та «заробіток». Заробіток отримується від слова навчання, а також зауважте, що кожне слово відокремлено від ключового слова -e.
$ grep -Я -e робота -e заробляю filea.txt
Наведене зображення показує цілі рядки в абзаці щодо слів, присутніх у команді. Як і наведені вище приклади, -Я проігнорував усі випадки дискримінації слів робота і заробляти.
Приклад 8
У цьому прикладі здійснюється пошук двох слів, присутніх у всіх файлах .txt розширення. Ці два слова відокремлюються -e, оскільки -e є правильним способом розділення двох слів. Отриманий результат матиме обидва слова, показані у всіх файлах розширення тексту. Отримана і відображається вся адреса файлу. -Я ігноруватиму чутливість до регістру та відображатиму обидва слова, присутні у всіх файлах.
$ grep -I -e робота -e заробіток / home / aqsayasin / *.txt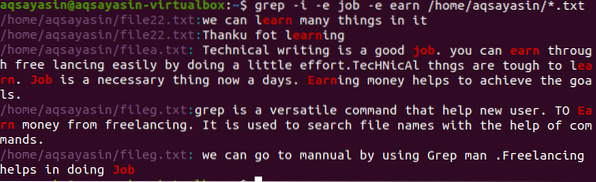
Висновок
У цьому посібнику ми використали найпростіший приклад для детального вивчення концепції чутливості до регістру. Ми намагалися з усіх сил пройти кожен аспект, щоб покращити знання щодо grep.


