У цій статті ми розглянемо основні способи використання групи за функціями в Python Panda. Усі команди виконуються в редакторі Pycharm.
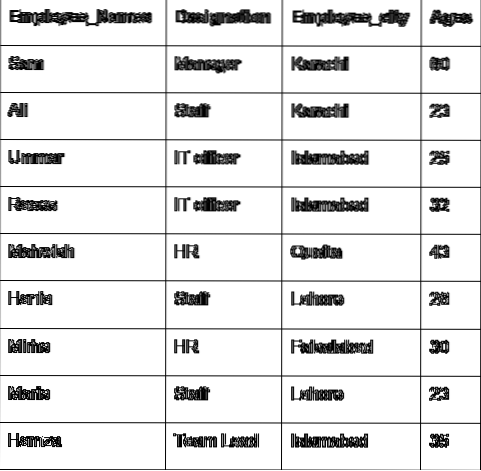
Обговоримо основну концепцію групи за допомогою даних працівника. Ми створили фрейм даних з деякими корисними відомостями про співробітників (Employee_Names, Designation, Employee_city, Age).
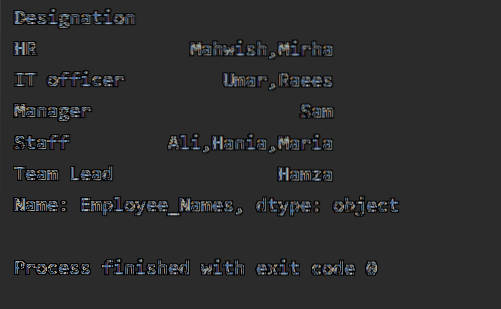
Конкатенація рядків за допомогою групи за функцією
Використовуючи функцію groupby, ви можете об'єднати рядки. Ті самі записи можна об'єднати за допомогою ',' в одній комірці.
Приклад
У наступному прикладі ми відсортували дані на основі стовпця "Позначення" співробітників і приєдналися до співробітників, які мають те саме позначення. Функція лямбда застосовується до "Employees_Name".
імпортувати панд як pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Позначення': ['Менеджер', 'Персонал', 'ІТ-спеціаліст', 'ІТ-спеціаліст', 'HR', 'Персонал', 'HR', 'Персонал', 'Керівник команди'],
'Місто співробітників': ['Карачі', 'Карачі', 'Ісламабад', 'Ісламабад', 'Кветта', 'Лахор', 'Фейслабад', 'Лахор', 'Ісламабад'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ("Позначення") ['Імена службовців'].apply (lambda Employee_Names: ','.приєднатися (Employee_Names))
друк (df1)
Коли виконується наведений вище код, відображається такий результат:
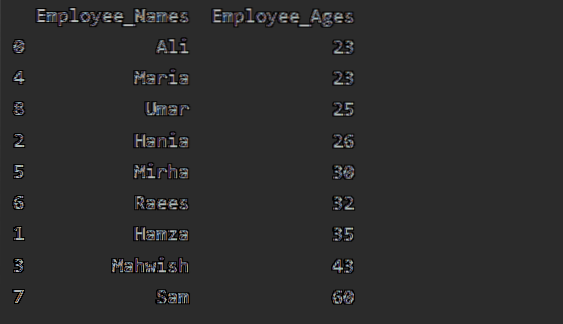
Сортування значень у порядку зростання
Використовуйте об'єкт groupby у звичайний фрейм даних, викликаючи '.to_frame () ', а потім використовуйте reset_index () для переіндексації. Сортування значень стовпців за допомогою виклику sort_values ().
Приклад
У цьому прикладі ми відсортуємо вік співробітника за зростанням. Використовуючи наступний фрагмент коду, ми отримали "Employee_Age" у порядку зростання за допомогою "Employee_Names".
імпортувати панд як pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Позначення': ['Менеджер', 'Персонал', 'ІТ-спеціаліст', 'ІТ-спеціаліст', 'HR', 'Персонал', 'HR', 'Персонал', 'Керівник команди'],
'Місто_працівника': ['Карачі', 'Карачі', 'Ісламабад', 'Ісламабад', 'Кветта', 'Лахор', 'Фейслабад', 'Лахор', 'Ісламабад'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Employee_Age'].сума ().to_frame ().reset_index ().сортувати_значення (за = 'Працівник_Вік')
друк (df1)
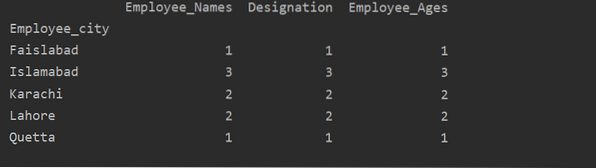
Використання агрегатів з groupby
Доступна низка функцій або агрегатів, які можна застосувати до груп даних, таких як count (), sum (), mean (), mediana (), mode (), std (), min (), max ().
Приклад
У цьому прикладі ми використовували функцію "count ()" з groupby для підрахунку працівників, які належать до одного і того ж "Employee_city".
імпортувати панд як pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Позначення': ['Менеджер', 'Персонал', 'ІТ-спеціаліст', 'ІТ-спеціаліст', 'HR', 'Персонал', 'HR', 'Персонал', 'Керівник команди'],
'Місто співробітників': ['Карачі', 'Карачі', 'Ісламабад', 'Ісламабад', 'Кветта', 'Лахор', 'Фейслабад', 'Лахор', 'Ісламабад'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city').рахувати()
друк (df1)
Як ви можете бачити наступний результат, у стовпцях Designation, Employee_Names та Employee_Age підрахуйте числа, що належать одному місту:
Візуалізуйте дані за допомогою groupby
За допомогою 'import matplotlib.pyplot ', ви можете візуалізувати свої дані у графіках.
Приклад
Тут наступний приклад візуалізує 'Employee_Age' за допомогою 'Employee_Nmaes' із заданого DataFrame за допомогою оператора groupby.
імпортувати панд як pdімпортувати matplotlib.pyplot як plt
dataframe = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Позначення': ['Менеджер', 'Персонал', 'ІТ-спеціаліст', 'ІТ-спеціаліст', 'HR', 'Персонал', 'HR', 'Персонал', 'Керівник команди'],
'Місто співробітників': ['Карачі', 'Карачі', 'Ісламабад', 'Ісламабад', 'Кветта', 'Лахор', 'Фейслабад', 'Лахор', 'Ісламабад'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
plt.clf ()
фрейм даних.groupby ('Employee_Names').сума ().ділянка (kind = 'bar')
plt.показати ()
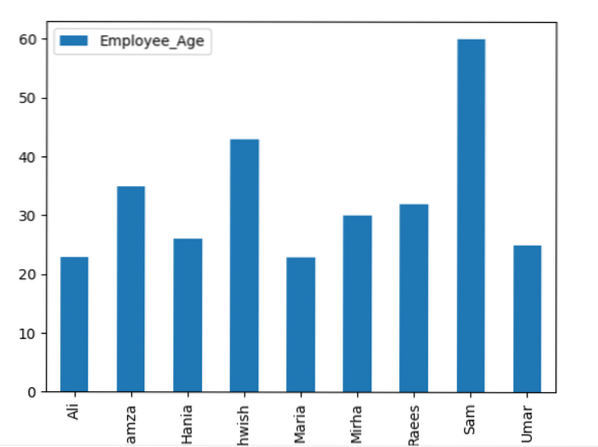
Приклад
Щоб побудувати графік з накопиченням за допомогою groupby, поверніть 'stacked = true' і використовуйте такий код:
імпортувати панд як pdімпортувати matplotlib.pyplot як plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Позначення': ['Менеджер', 'Персонал', 'ІТ-спеціаліст', 'ІТ-спеціаліст', 'HR', 'Персонал', 'HR', 'Персонал', 'Керівник команди'],
'Місто співробітників': ['Карачі', 'Карачі', 'Ісламабад', 'Ісламабад', 'Кветта', 'Лахор', 'Фейслабад', 'Лахор', 'Ісламабад'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df.groupby (['Employee_city', 'Employee_Names']).розмір ().розкласти ().ділянка (kind = 'bar', stacked = True, fontsize = '6')
plt.показати ()
На наведеному нижче графіку кількість штатних співробітників, які належать до одного міста.
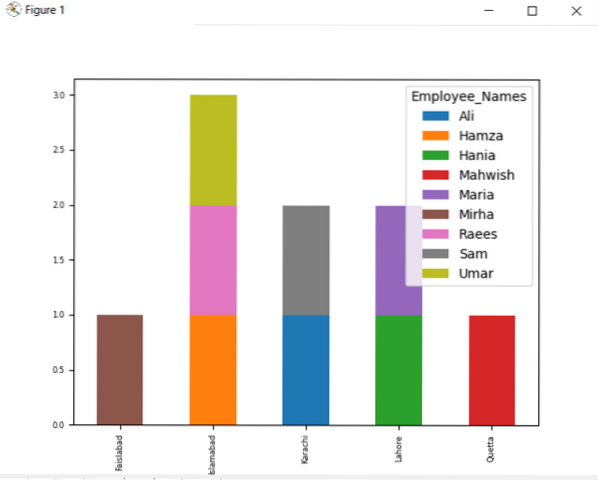
Змініть назву стовпця з групою на
Ви також можете змінити агреговане ім'я стовпця на якесь нове змінене ім'я наступним чином:
імпортувати панд як pdімпортувати matplotlib.pyplot як plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Позначення': ['Менеджер', 'Персонал', 'ІТ-спеціаліст', 'ІТ-спеціаліст', 'HR', 'Персонал', 'HR', 'Персонал', 'Керівник команди'],
'Місто співробітників': ['Карачі', 'Карачі', 'Ісламабад', 'Ісламабад', 'Кветта', 'Лахор', 'Фейслабад', 'Лахор', 'Ісламабад'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_Names') ['Позначення'].сума ().reset_index (name = 'Призначення працівника')
друк (df1)
У наведеному вище прикладі ім'я "Позначення" змінено на "Employee_Designation".
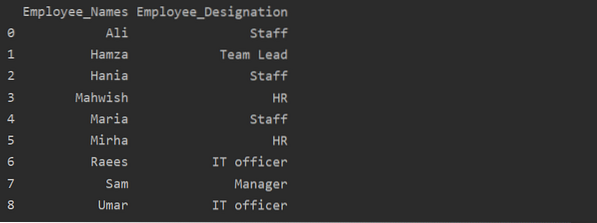
Отримати групу за ключем або значенням
За допомогою оператора groupby ви можете отримати подібні записи або значення з кадру даних.
Приклад
У наведеному нижче прикладі ми маємо групові дані на основі "Позначення". Потім група "Персонал" отримується за допомогою .getgroup ('Персонал').
імпортувати панд як pdімпортувати matplotlib.pyplot як plt
df = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Позначення': ['Менеджер', 'Персонал', 'ІТ-спеціаліст', 'ІТ-спеціаліст', 'HR', 'Персонал', 'HR', 'Персонал', 'Керівник команди'],
'Місто співробітників': ['Карачі', 'Карачі', 'Ісламабад', 'Ісламабад', 'Кветта', 'Лахор', 'Фейслабад', 'Лахор', 'Ісламабад'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
екстракт_значення = df.groupby ('Позначення')
print (екстракт_визначення.get_group ('Персонал'))
У вікні виводу відображається такий результат:

Додати значення до списку груп
Подібні дані можна відобразити у вигляді списку за допомогою оператора groupby. Спочатку згрупуйте дані на основі умови. Потім, застосувавши функцію, ви можете легко внести цю групу до списків.
Приклад
У цьому прикладі ми вставили подібні записи до списку груп. Усі співробітники поділяються на групу на основі 'Employee_city', а потім, застосовуючи функцію 'Lambda', ця група отримується у вигляді списку.
імпортувати панд як pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Позначення': ['Менеджер', 'Персонал', 'ІТ-спеціаліст', 'ІТ-спеціаліст', 'HR', 'Персонал', 'HR', 'Персонал', 'Керівник команди'],
'Місто співробітників': ['Карачі', 'Карачі', 'Ісламабад', 'Ісламабад', 'Кветта', 'Лахор', 'Фейслабад', 'Лахор', 'Ісламабад'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df1 = df.groupby ('Employee_city') ['Employee_Names'].застосовувати (lambda group_series: group_series.tolist ()).reset_index ()
друк (df1)
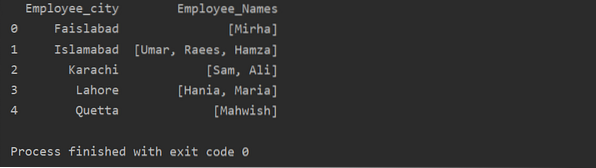
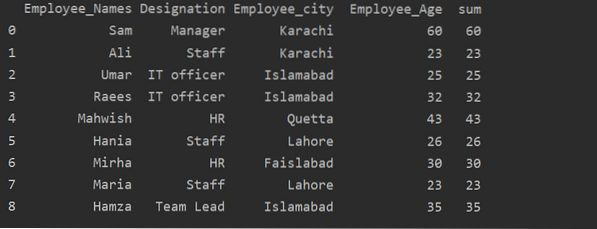
Використання функції перетворення з groupby
Співробітники групуються відповідно до їх віку, ці значення складаються, і за допомогою функції "перетворення" в таблицю додається новий стовпець:
імпортувати панд як pddf = pd.DataFrame (
'Employee_Names': ['Sam', 'Ali', 'Umar', 'Raees', 'Mahwish', 'Hania', 'Mirha', 'Maria', 'Hamza'],
'Позначення': ['Менеджер', 'Персонал', 'ІТ-спеціаліст', 'ІТ-спеціаліст', 'HR', 'Персонал', 'HR', 'Персонал', 'Керівник команди'],
'Місто співробітників': ['Карачі', 'Карачі', 'Ісламабад', 'Ісламабад', 'Кветта', 'Лахор', 'Фейслабад', 'Лахор', 'Ісламабад'],
'Employee_Age': [60, 23, 25, 32, 43, 26, 30, 23, 35]
)
df ['сума'] = df.groupby (['Employee_Names']) ['Employee_Age'].transform ('сума')
друк (df)
Висновок
У цій статті ми досліджували різні способи використання оператора groupby. Ми показали, як ви можете розділити дані на групи, і, застосовуючи різні агрегації або функції, ви можете легко отримати ці групи.


