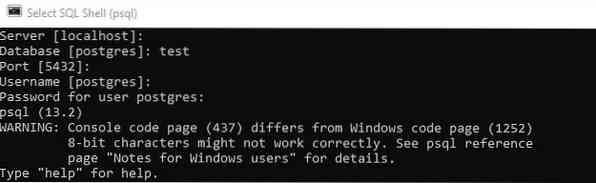
Щоб зрозуміти агрегований метод ARRAY_Agg (), потрібно виконати кілька прикладів. Для цього відкрийте оболонку командного рядка PostgreSQL. Якщо ви хочете увімкнути інший Сервер, зробіть це, вказавши його ім’я. В іншому випадку залиште місце порожнім і натисніть кнопку Enter, щоб перейти до бази даних. Якщо ви хочете використовувати базу даних за замовчуванням, e.g., Postgres, потім залиште його як є і натисніть Enter; в іншому випадку напишіть ім'я бази даних, e.g., "Тест", як показано на зображенні нижче. Якщо ви хочете використовувати інший порт, випишіть його, інакше просто залиште його таким, як є, і натисніть Enter, щоб продовжити. Він попросить вас додати ім’я користувача, якщо ви хочете перейти на інше ім’я користувача. Додайте ім’я користувача, якщо хочете, інакше просто натисніть “Enter”. Врешті-решт, ви повинні надати свій поточний пароль користувача, щоб почати використовувати командний рядок, використовуючи цього конкретного користувача, як показано нижче. Після успішного введення всієї необхідної інформації, ви готові піти.
Використання ARRAY_AGG в одній колонці:
Розглянемо таблицю “людина” в базі даних “тест”, що має три стовпці; “Id”, “name” та “age”. У стовпці "id" є ідентифікатори всіх осіб. Тоді як поле «ім’я» містить імена осіб, а стовпець «вік» - вік усіх осіб.
>> ВИБЕРІТЬ * ВІД людини;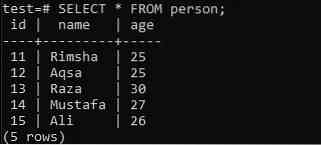
Залежно від таблиці накладних витрат, ми повинні застосувати агрегований метод ARRAY_AGG для повернення списку масиву всіх імен таблиці через стовпець “name”. При цьому вам потрібно використовувати функцію ARRAY_AGG () у запиті SELECT, щоб отримати результат у вигляді масиву. Спробуйте заявлений запит у своїй командній оболонці та отримайте результат. Як бачите, у нас є нижченаведений вихідний стовпець “array_agg”, що має імена, перелічені в масиві для того самого запиту.
>> ВИБЕРІТЬ ARRAY_AGG (ім’я) ВІД людини;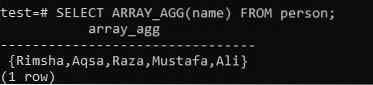
Використання ARRAY_AGG у кількох стовпцях із реченням ORDER BY:
Приклад 01:
Застосовуючи функцію ARRAY_AGG до кількох стовпців під час використання речення ORDER BY, розглянемо одну і ту ж таблицю “людина” в “тесті” бази даних, що має три стовпці; “Id”, “name” та “age”. У цьому прикладі ми будемо використовувати речення GROUP BY.
>> ВИБЕРІТЬ * ВІД людини;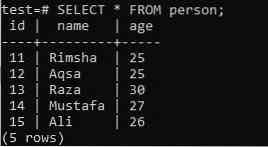
Ми об'єднували результат запиту SELECT у список масивів, використовуючи два стовпці "name" та "age". У цьому прикладі ми використовували пробіл як спеціальний символ, який до цього часу використовувався для об’єднання обох цих стовпців. З іншого боку, ми отримували стовпець “id” окремо. Результат об'єднаного масиву буде показано в стовпці "персональні дані" під час виконання. Набір результатів спочатку буде згруповано за “ідентифікатором” особи та відсортовано за зростанням поля “ідентифікатор”. Давайте спробуємо наведену нижче команду в оболонці і самі побачимо результати. Ви можете бачити, що у нас є окремий масив для кожного об’єднаного значення віку імен на зображенні нижче.
>> ВИБЕРІТЬ ідентифікатор, ARRAY_AGG (ім'я || "|| вік) як персональні дані ВІД особи ГРУПА ЗА ІДЕНТОМ ЗАМОВИТИ ЗА ідентифікатором;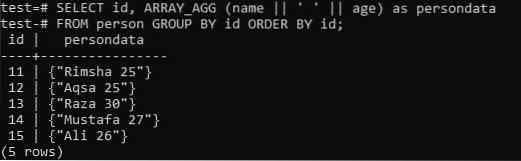
Приклад 02:
Розглянемо нещодавно створену таблицю “Працівник” у рамках “тесту” бази даних, що має п’ять стовпців; “Ідентифікатор”, “ім’я”, “зарплата”, “вік” та “електронна адреса”. У таблиці зберігаються всі дані про 5 співробітників, що працюють у компанії. У цьому прикладі ми будемо використовувати спеціальний символ '-' для об'єднання двох полів замість того, щоб використовувати пробіл, використовуючи речення GROUP BY та ORDER BY.
>> ВИБРАТИ * ВІД Співробітника;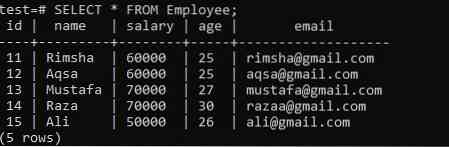
Ми об'єднуємо дані двох стовпців, "ім'я" та "електронна пошта" в масив, використовуючи "-" між ними. Як і раніше, ми чітко витягуємо стовпець “id”. Результати конкатенованих стовпців відображатимуться як “пусті” під час виконання. Набір результатів спочатку збирається за “ідентифікатором” людини, а потім він буде організований у порядку зростання стовпця “ідентифікатор”. Давайте спробуємо дуже подібну команду в оболонці з незначними змінами і побачимо наслідки. З наведеного нижче результату ви отримали окремий масив для кожного об’єднаного значення імені та електронної пошти, представленого на малюнку, тоді як у кожному значенні використовується знак «-».
>> ВИБЕРІТЬ ідентифікатор, ARRAY_AGG (ім'я || '-' || електронна пошта) ЯК ВІД ФОРМИ Співробітника ГРУПА ЗА ІД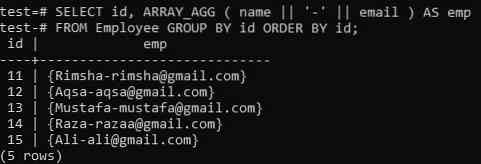
Використання ARRAY_AGG у кількох стовпцях без пункту ORDER BY:
Ви також можете спробувати метод ARRAY_AGG у будь-якій таблиці, не використовуючи пропозиції ORDER BY та GROUP BY. Припустимо щойно створену таблицю “актор” у вашій “тест” старої бази даних, що має три стовпці; “Id”, “fname” та “lname”. У таблиці містяться дані про імена та прізвища актора, а також їх ідентифікатори.
>> ВИБЕРІТЬ * З актора;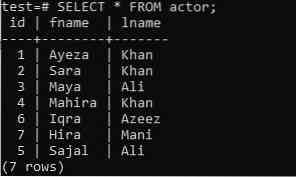
Отже, об'єднайте два стовпці "fname" і "lname" у списку масивів, використовуючи пробіл між ними, так само, як це було зроблено в останніх двох прикладах. Ми чітко не вийняли стовпець 'id', а також використовували функцію ARRAY_AGG у запиті SELECT. Отриманий масив, об'єднаний стовпець, буде представлений як "актори". Спробуйте вказаний нижче запит у командній оболонці та погляньте на отриманий масив. Ми отримали один масив із представленим значенням об’єднаного імені та електронної пошти, відокремленим комою від результату.

Висновок:
Нарешті, ви майже закінчили виконувати більшість прикладів, необхідних для розуміння агрегованого методу ARRAY_AGG. Спробуйте більше їх у своєму кінці для кращого розуміння та знань.


