Встановлення Tesseract OCR в Linux
Tesseract OCR доступний за замовчуванням для більшості дистрибутивів Linux. Ви можете встановити його в Ubuntu, використовуючи команду нижче:
$ sudo apt встановити tesseract-ocrДетальні вказівки щодо інших дистрибутивів доступні тут. Незважаючи на те, що Tesseract OCR за замовчуванням доступний у сховищах багатьох дистрибутивів Linux, рекомендується встановити останню версію за посиланням, згаданим вище, для підвищення точності та синтаксичного аналізу.
Встановлення підтримки для додаткових мов у Tesseract OCR
Tesseract OCR включає підтримку виявлення тексту понад 100 мовами. Однак ви отримуєте підтримку для виявлення тексту англійською мовою лише за умови встановлення за замовчуванням в Ubuntu. Щоб додати підтримку для розбору додаткових мов в Ubuntu, запустіть команду в такому форматі:
$ sudo apt встановити tesseract-ocr-hinНаведена вище команда додасть підтримку мови хінді до Osecer Tesseract. Іноді ви можете отримати кращу точність і результати, встановивши підтримку мовних сценаріїв. Наприклад, встановлення та використання пакету tesseract для сценарію Devanagari “tesseract-ocr-script-deva” дало мені набагато точніші результати, ніж використання пакета “tesseract-ocr-hin”.
В Ubuntu ви можете знайти правильні імена пакетів для всіх мов та сценаріїв, виконавши команду нижче:
$ apt-cache пошук tesseract-Визначивши правильне ім'я пакета для встановлення, замініть рядок “tesseract-ocr-hin” ним у першій команді, зазначеній вище.
Використання Tesseract OCR для вилучення тексту із зображень
Візьмемо приклад зображення, показано нижче (взято зі сторінки Вікіпедії для Linux):

Щоб витягти текст із зображення вище, вам потрібно виконати команду в наступному форматі:
захоплення $ tesseract.вихід png -l англЗапуск наведеної вище команди дає такий результат:
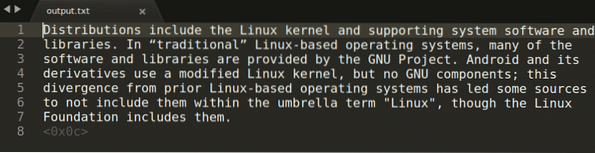
У наведеній вище команді “захоплення.png ”відноситься до зображення, з якого потрібно витягти текст. Потім захоплений висновок зберігається у “виході.txt ”. Ви можете змінити мову, замінивши аргумент “eng” на власний вибір. Щоб переглянути всі допустимі мови, запустіть команду нижче:
$ tesseract --list-langsНа ній відображатимуться абревіатурні коди для всіх мов, що підтримуються системою OCR від Tesseract. За замовчуванням він відображатиме лише "eng" як вихідний файл. Однак якщо ви встановлюєте пакети для додаткових мов, як пояснювалося вище, ця команда перелічить більше мов, які ви можете використовувати для виявлення тексту (як 3-літерні коди мови ISO 639).
Якщо зображення містить текст кількома мовами, спочатку визначте основну мову, а потім додаткові мови, розділені знаками плюс.
захоплення $ tesseract.вихід png -l eng + fraЯкщо ви хочете зберегти вихідні дані як PDF-файл, який можна шукати, запустіть команду в наступному форматі:
захоплення $ tesseract.вихід png -l eng pdfЗверніть увагу, що PDF-файл, який можна знайти, не міститиме жодного редагованого тексту. Він включає оригінальне зображення з додатковим шаром, що містить розпізнаний текст, накладений на зображення. Отже, хоча ви зможете точно шукати текст у файлі PDF за допомогою будь-якого зчитувача PDF, ви не зможете редагувати текст.
Ще слід зазначити, що точність розпізнавання тексту значно зростає, якщо файл зображення має високу якість. Завжди вибираючи, завжди використовуйте формати файлів без втрат або файли PNG. Використання файлів JPG може дати не найкращі результати.
Витяг тексту з багатосторінкового PDF-файлу
Tesseract OCR спочатку не підтримує вилучення тексту з файлів PDF. Однак можна витягти текст із багатосторінкового PDF-файлу, перетворивши кожну сторінку у файл зображення. Виконайте команду нижче, щоб перетворити файл PDF у набір зображень:
Файл $ pdftoppm -png.вихід PDFДля кожної сторінки файлу PDF ви отримаєте відповідний “output-1.png "," вихід-2.png ”, тощо.
Тепер, щоб витягти текст із цих зображень за допомогою однієї команди, вам доведеться використовувати цикл “for” у команді bash:
$ за я в *.PNG; зробити тессеракт "$ i" "output- $ i" -l eng; зроблено;Запуск вищевказаної команди витягне текст із усіх “.png ”, знайдених у робочому каталозі, і розпізнаний текст зберігається у“ output-original_filename.txt ”. Ви можете змінити середню частину команди відповідно до своїх потреб.
Якщо ви хочете об'єднати всі текстові файли, що містять розпізнаний текст, запустіть команду нижче:
$ кішка *.txt> приєднався.txtПроцес вилучення тексту з багатосторінкового PDF-файлу у PDF-файли, які можна шукати, майже однаковий. Вам потрібно надати додатковий аргумент “pdf” для команди:
$ за я в *.PNG; зробити тессеракт "$ i" "output- $ i" -l eng pdf; зроблено;Якщо ви хочете об'єднати всі PDF-файли, які можна знайти, що містять розпізнаний текст, запустіть команду нижче:
$ pdfunite *.pdf приєднався.pdfІ “pdftoppm”, і “pdfunite” встановлюються за замовчуванням на останній стабільній версії Ubuntu.
Переваги та недоліки вилучення тексту у файлах TXT та PDF-файлах, які можна шукати
Якщо ви розпакуєте розпізнаний текст у файли TXT, ви отримаєте можливість редагування тексту. Однак будь-яке форматування документа буде втрачено (жирний шрифт, курсив тощо). PDF-файли, які можна шукати, збережуть оригінальне форматування, але ви втратите можливості редагування тексту (ви все ще можете копіювати необроблений текст). Якщо ви відкриєте PDF-файл, який можна шукати, у будь-якому редакторі PDF, ви отримаєте вбудовані зображення у файл, а не вихідний текст. Перетворення PDF-файлів, які можна шукати, у HTML або EPUB також дасть вам вбудовані зображення.
Висновок
Tesseract OCR є одним з найбільш широко використовуваних OCR двигунів на сьогодні. Це безкоштовний відкритий код і підтримує більше ста мов. Використовуючи Tesseract OCR, обов’язково використовуйте зображення з високою роздільною здатністю та коригуйте мовні коди в аргументах командного рядка, щоб підвищити точність розпізнавання тексту.


