Щоб зрозуміти концепцію повнотекстового пошуку, вам слід згадати знання пошуку за шаблоном за допомогою ключового слова LIKE. Отже, припустимо таблицю "людина" в базі даних "тест" із наступними записами в ній.
>> ВИБЕРІТЬ * ВІД людини;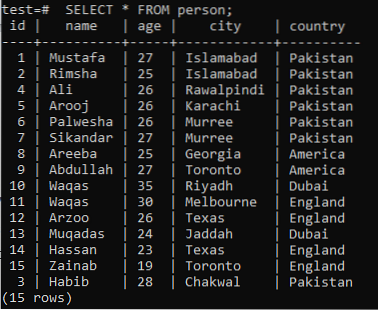
Припустимо, ви хочете отримати записи цієї таблиці, де стовпець 'name' має символ 'i' в будь-якому з його значень. Спробуйте наведений нижче запит SELECT під час використання речення LIKE у командній оболонці. З вихідних даних видно, що у нас є лише 5 записів для цього конкретного символу "i" у стовпці "name".
>> ВИБЕРІТЬ * ВІД особи, ДЕ ім’я ПОДОБАЄТЬСЯ „% i% ';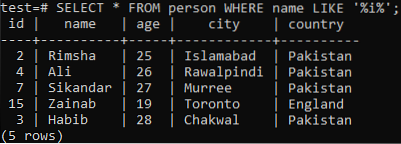
Використання Tvsector:
Іноді корисно використовувати ключове слово LIKE для швидкого пошуку за шаблоном, хоча слово є. Можливо, ви могли б подумати про використання стандартних виразів, і, хоча це можливо, альтернатива, регулярні вирази одночасно сильні та мляві. Наявність процедурного вектора для цілих слів у тексті, просторічний опис цих слів - набагато ефективніший спосіб вирішення цієї проблеми. Для реагування на нього було створено концепцію повного пошуку тексту та тип даних tsvector. У PostgreSQL є два методи, які роблять саме те, що ми хочемо:
- To_tvsector: Використовується для складання списку лексем (ts означає "пошук тексту").
- To_tsquery: Використовується для пошуку у векторі випадків виникнення певних термінів або фраз.
Приклад 01:
Почнемо з простої ілюстрації створення вектора. Припустимо, ви хочете зробити вектор для рядка: «Деякі люди мають кучеряве каштанове волосся завдяки правильному чищенню щітки.". Отже, вам потрібно написати функцію to_tvsector () разом із цим реченням у дужках запиту SELECT, як додано нижче. З вихідних даних видно, що це дасть вектор посилань (позицій файлів) для кожного маркера, а також там, де терміни з невеликим контекстом, такі як статті () та сполучники (та, або), свідомо ігноруються.
>> ВИБЕРІТЬ to_tsvector ('Деякі люди мають кучеряві каштанові волосся завдяки правильному чищенню щіткою');
Приклад 02:
Припустимо, у вас є два документи, в яких містяться дані. Щоб зберегти ці дані, зараз ми будемо використовувати реальний приклад генерації токенів. Припустимо, ви створили таблицю "Дані" у вашій базі даних "тест" із кількома стовпцями в ній, використовуючи нижченаведений запит СТВОРИТИ ТАБЛИЦЮ. Не забудьте створити в ньому стовпець типу TVSECTOR із назвою 'маркер'. З наведених нижче результатів ви можете поглянути на створену таблицю.
>> СТВОРИТИ Дані ТАБЛИЦІ (Id СЕРІЙНИЙ ПЕРВИННИЙ КЛЮЧ, інформаційний ТЕКСТ, маркер TSVECTOR);
Тепер нам належить додати загальні дані обох документів до цієї таблиці. Тож спробуйте виконати наведену нижче команду INSERT у вашій оболонці командного рядка. Нарешті, записи обох документів були успішно додані до таблиці "Дані".
>> ВСТАВИТИ В ЗНАЧЕННЯ даних (інформації) ('Дві помилки ніколи не можуть зробити одну помилку.'), (' Він той, хто вміє грати у футбол.'), (' Чи можу я взяти в цьому роль?'), (' Болю всередині людини неможливо зрозуміти '), (' Принеси персик у своє життя);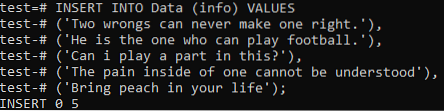
Тепер вам доведеться колонізувати стовпець маркерів обох документів з їх конкретним вектором. Зрештою, простий запит UPDATE заповнить стовпець лексем відповідним вектором для кожного файлу. Отже, вам потрібно виконати вказаний нижче запит у командній оболонці, щоб зробити це. Результат показує, що оновлення остаточно здійснено.
>> ОНОВЛЕННЯ даних f1 Встановити маркер = to_tsvector (f1.інформація) ВІД даних f2;
Тепер, коли у нас все це на місці, повернімось до нашої ілюстрації "може один" за допомогою сканування. To_tsquery з оператором AND, як уже зазначалося, не має різниці між розташуванням файлів у файлах, як показано з результатів, зазначених нижче.
>> ВИБЕРІТЬ ідентифікатор, інформацію ВІД даних WHERE маркер @@ to_tsquery ('can & one');
Приклад 04:
Щоб знайти слова, які «поруч», ми спробуємо той самий запит із «<->'оператор. Зміна відображається у вихідних даних нижче.
>> ВИБЕРІТЬ ідентифікатор, інформацію ВІД даних WHERE маркер @@ to_tsquery ('can <-> один ');
Ось приклад прямого слова поруч із іншим.
>> ВИБЕРІТЬ ідентифікатор, інформацію ВІД даних WHERE маркер @@ to_tsquery ('one <-> біль ');
Приклад 05:
Ми знайдемо слова, які не знаходяться одразу поруч, використовуючи число в операторі відстані для посилання на відстань. Близькість між "принести" та "життям" - це 4 слова, крім відображеного зображення.
>> ВИБЕРІТЬ * ВІД даних ДЕ, де маркер @@ to_tsquery ('принести <4> життя ');
Щоб перевірити близькість між словами майже 5 слів, додано нижче.
>> ВИБЕРІТЬ * ВІД даних WHERE маркер @@ to_tsquery ('неправильно <5> праворуч ');
Висновок:
Нарешті, ви зробили всі прості та складні приклади повнотекстового пошуку, використовуючи оператори та функції To_tvsector та to_tsquery.


